はじめに
初めまして、レバレジーズ株式会社FEエンジニアの森山です。
今回は、React開発におけるコンポーネントの定義方法の1つの解をご紹介します。
結論
結論を簡潔に記載すると以下です。
- ロジックをUIロジックと業務ロジックに切り分ける。
- UIとUIロジックは密結合させて再利用性を高める。
- UIと業務ロジックは疎結合にして再利用性を高める。
背景や具体的な例は後述します。
なぜこの記事を書いたのか
私が調べた限りではReactにおけるコンポーネントの定義方法におけるベストプラクティスが存在しないからです。
Reactの公式ドキュメントにおいてもコンポーネントの定義方法の方針は記載が無いかと思います。これはReactの思想として開発者がプロジェクトの規模や特性を考慮してある程度の自由度を持って開発できることを尊重したのではないかと考えています。
自由度が高いと開発方法の手段が増えます。手段が多いのでどの開発方法がベストなのかReactの開発者も日々、様々な開発手段を試行錯誤しブログを執筆したり、議論しています。
プロジェクトに合わせて最適な手段を選択できる余地があるのは良いことです。
しかし、その自由度の高さをそのままにしておく。
つまりコンポーネントの定義ルールが曖昧な状態でプロジェクトが進むと以下のようなことが起きる可能性があります。
- 開発者が各々、自由に開発を進める。
- システム内に様々なコンポーネント実装の流派が生まれ、自分の実装が正しいか判断できなくなる。
- 実装方法の正解が分からず、何をどこに書くべきか自信がないため実装スピードが落ちる。
- 修正を加える度に複雑さが増し、再利用性も低下する。
- 最終的にプロジェクト当初では1時間と見積もっていた規模の修正タスクに3時間かかってしまう。
上記を払拭するためにも、FEエンジニアが納得感を持ってコンポーネント実装ができるルールを作る必要がありました。
コンポーネント実装における課題はUIとロジックの関係性
よく議論されるのは以下です。
- コンポーネントのUIとロジックを密結合にするのか、疎結合にするのか。
- 疎結合の場合はHooksを活用するのか、コンポーネント自体を分けるのか。
そもそもReactにおけるロジックとは何か?
そもそもこの記事においてのReactにおけるロジックとはreturnでDOMを返す前の処理やUIの表示分岐のことです。
const Component = () => {
const [state, setState] = useState(true);
const data = fetch('https://api.endpoint');
// ...
// ここから上がロジック
return (
<>
<h1>{data.title}</h1>
<!-- UI表示の分岐ロジック -->
<p>{state ? 'on' : 'off' }</p>
</>
)
}
一言でロジックと言っても、以下の2種類に分類できると考えています。
UIロジック
UIロジックとは、UIの制御のみを目的としたロジックです。
具体例としては以下の様な挙動が挙げられます。
- トグルボタンのon/offの制御
- プルダウンの開閉の制御
const Toggle = ({ isActive }) => {
return isActive ? <ActiveToggle/> : <InActiveToggle/>
}
UIロジックは、「業務に依存しない」純粋なUIのふるまいの制御になります。
業務ロジック
業務ロジックとは業務ルールを実現するためのロジックです。
表示する数値に単位を付ける等の業務独自の「表示データの整形」や、「APIの発行」等が該当します。
const Price = () => {
const { data } = fetch('https://api.endpoint');
const { quantity, unitPrice ,taxRate, shippingCost } = data;
const basePrice = quantity * unitPrice;
const price = (basePrice + shippingCost) * taxRate;
return (
<>
<h1>価格: {price}円</h1>
<p>内訳</p>
<ul>
<li>個数: {quantity}個</li>
<li>単価: {unitPrice}円</li>
<li>税率: {taxRate}%</li>
<li>送料: {shippingCost}円</li>
</ul>
</>
)
}
UIとロジックの密結合、疎結合の使い分け
UIとロジックは必ずしも「密結合が良い」とか「疎結合が良い」とは言い切れません。
前述したロジックの分類(UIロジックと業務ロジック)によって変わるかと思います。
コンポーネント単体で見るときれいに切り分けられている記事も見かけます。
しかしその1部品をルール化してプロジェクト全体に適応しようとすると、プロジェクトの規模や業務ロジックの複雑さも起因してどうしてもルールを守るのが苦しい場面に遭遇します。そして苦しいながらもルールを守るために、意味もなく複雑度の高いコンポーネントが生み出されます。
上手くUIとロジックの関係性をルール化するためにはロジックの分類を考慮する必要があります。
私の考えでは以下の使い分けが望ましいです。
UIとUIロジックは密結合
UIと業務ロジックは疎結合
UIロジックと業務ロジックは疎結合
具体的な実装例
具体的にどのように実装すべきか一般的なAtomic designに沿った分類のコードで説明します。
まず各コンポーネントの区分けは以下になります。
※ templatesとpagesはここでは省きます。
- atoms
- コンポーネントの最小単位。
- ロジックは持たない。
- ステートレスなコンポーネント。
- システム全体で流用できる。
- molecules
- atoms、moleculesの複合コンポーネント。
- UIロジックを持つことがある。
- ステートレスなコンポーネント。
- システム全体で流用できる。
- organisms
- atoms、moleculesの複合コンポーネント。
- 業務のドメイン情報をDOMに持つことがある。
- そのためシステム全体で流用できるとは限らない。
- APIとの疎通や業務ロジックを持つことがある。
- そのためステートレスとは限らない。
atoms
// アクティブなラジオボタン
const ActiveRadio = () => {
return (
<div style={{
width: 15px;
height: 15px;
backgroundColor: white;
border: 1px solid black;
borderRadius: 10px;
display: flex;
alignItems: center;
justifyContent: center;
}}>
<span style={{
width: 5px;
height: 5px;
backgroundColor: blue;
borderRadius: 10px;
}} />
</div>
)
}
const Title = ({ text }) => {
return <h1 style={{ fontSize: 20px }}>{text}</h1>
}
atomsの特徴
コンポーネントの最小単位。
ロジックは持たない。
ステートレスなコンポーネント。
システム全体で流用される。
atoms実装の注意点
atomsでは基本的に
returnの上にロジックが書かれることはありません。
というのも意識的にロジックを書かないというよりかは、「最小単位」のコンポーネントなので責務も小さく自然と書く必要がなくなるイメージです。
ロジックを書く必要がある場合はそのatomsは「最小単位」として扱うべきでない可能性があります。
更に最小のコンポーネントになり得ないかを疑う余地があるかと思います。
molecules
import { ActiveRadio, InActiveRadio } from '~/atoms/radio';
// on/offができるラジオボタン
const Radio = ({ isActive }) => {
return isActive ? <ActiveRadio /> : <InActiveRadio />
}
import { Button } from '~/atoms/button';
// ファイルアップロードフォーム & ボタン
const FileUpload = ({ name, text }) => {
const ref = useRef(null);
const onClickInput = () => ref.current.click();
return (
<>
<Button onClick={onClickInput} >{text}</Button>
<input hidden name={name} ref={ref} type="file" />
</>
);
}
moleculesの特徴
atoms、moleculesの複合コンポーネント。
UIロジックを持つことがある。
ステートレスなコンポーネント。
システム全体で流用される。
上記のラジオボタンのようにコード量が少なくても「他のコンポーネントに依存」していればmoleculesに該当します。
ここがatomsとmoleculesの一番の違いです。
molecules実装の注意点①
moleculesにおけるUIロジックとUIは前述の通り「密結合」にするのが望ましいです。
なぜなら、依存関係が簡潔になりやすいためです。
例えば、以下のようにUIロジックを
Custom hookで共通化したとします。
全てのpulldownに共通する処理
// usePulldown.ts
export const usePulldown = () => {
return ...
}
一般的なプルダウン
// Pulldown.tsx
const Pulldown = () => {
const pulldownProps = usePulldown()
return <Pulldown {...plldownProps}/>
}
検索可能なプルダウン
// SearchPulldown.tsx
const SearchPulldown = () => {
const pulldownProps = usePulldown()
// ... SearchPulldown独自のロジック
return (
<>
<!-- other component -->
<Pulldown {...plldownProps}/>
</>
)
}
複数選択可能なプルダウン
// MultiPulldown.tsx
const MultiPulldown = () => {
const pulldownProps = usePulldown()
// ... MultiPulldown独自のロジック
return (
<>
<!-- other component -->
<Pulldown {...plldownProps}/>
</>
)
}
ここで
usePulldownの処理の中で
SearchPulldown.tsxのみに例外的な処理の追加が必要になったとします。
根本的な対処としては
usePulldownの中から例外的な処理が入る部分を切り出して他の
Pulldownや
MultiPulldownにも変更箇所のコードを移植することになるかと思います。
しかし元々一元管理されていたコードをわざわざ重複させる書き方はDRY原則にも反します。
大抵は以下のように
if文を一行入れて例外的な処理を走らせるような直感的な対処をしてしまいます。
// usePulldown.ts
export const usePulldown = (type) => {
+ if(type === 'searchPulldown') doSomething();
return ...
}
依存される側の
usePulldownが依存する側のコンポーネントの情報を保持することになります。
こうなると双方向に依存が発生し依存関係がおかしなことになります。
これはReactによらずプログラミング全般として良くない実装かと思います。
しかしReact開発で上記のように似たようなふるまいのコンポーネントが複数生成されて開発規模が大きくなると自然とやってしまいがちです。
そもそもこういった修正が発生しないためにも「UIロジック」と「DOM」は密結合に実装し、コンポーネント同士の独立性を高める方が各コンポーネントの拡張性も高くなります。
molecules層で複雑なUIのふるまいを持つことは少ないので1ファイルに「UIロジック」と「DOM」を密結合に実装しても50行前後に収めて可読性を担保することも可能なはずです。
molecules実装の注意点②
moleculesコンポーネントはシステム全体で活用できるレベルの再利用性を持つことが望ましいです。
システム全体で活用できるとは特定の業務ドメインに縛られないということです。
例えば以下のファイルアップロードボタンは汎用性が高く基本的にどんな場面でも活用できるかと思います。
import { Button } from '~/atoms/button';
// ファイルアップロードフォーム & ボタン
const FileUpload = ({ name, text }) => {
const ref = useRef(null);
const onClickInput = () => ref.current.click();
return (
<>
<Button onClick={onClickInput} >{text}</Button>
<input hidden name={name} ref={ref} type="file" />
</>
);
}
逆に特定の業務ドメインに縛られているとは以下のような状態です。
違いはボタンの名前が固定値になっただけです。
import { Button } from '~/atoms/button';
// ファイルアップロードフォーム & ボタン
const FileUpload = ({ name }) => {
const ref = useRef(null);
const onClickInput = () => ref.current.click();
return (
<>
<Button onClick={onClickInput} >プロフィール画像のアップロード</Button>
<input hidden name={name} ref={ref} type="file" />
</>
);
}
どんなシステムを開発しているかの前提もないですが、
上記のファイルアップロードボタンはユーザ情報の登録や編集を担う画面でしか活用できないコンポーネントになることが想像できます。
もしシステムが商品登録等の機能を持っていたらそちらでもファイルアップロードボタンは必要になりそうです。
しかし上記のように「特定の業務ドメイン」に限定されたコンポーネントだと再利用はできません。
再利用性の低いコンポーネントがmoleculesレベルで存在しているとシステムの規模が大きくなった時に以下のどちらかの苦しい対処が発生します。
利用箇所が限定的なコンポーネントが極端に増える
無理くりatomsをpages内で組み合わせて実装
なのでmoleculesでは特定の業務ドメインに縛られないコンポーネントであるべきです。
特定の業務ドメインとは何か
特定の業務ドメインとは何かについてさらに詳しく触れます。
単純に「業務ドメイン」とは言わずに「特定の業務ドメイン」と呼んでいるのには意味があります。
極端な例ですが、開発するシステムが商品管理システムでそれ以外の情報を扱わなかったとします。
この場合には、特定の業務ドメインは「商品登録機能、商品編集機能、商品削除機能」が該当します。
なので以下のようなコンポーネントが実装されてもシステム全体で活用できるのでmoleculesとして成立します。
import { Button } from '~/atoms/button';
// ファイルアップロードフォーム & ボタン
const FileUpload = ({ name }) => {
const ref = useRef(null);
const onClickInput = () => ref.current.click();
return (
<>
<Button onClick={onClickInput} >商品画像のアップロード</Button>
<input hidden name={name} ref={ref} type="file" />
</>
);
}
ただシステムが以下のような構成だと上記のコンポーネントはmoleculesとして成立しません。
molecules実装の注意点まとめ
長くなりましたが特に注意すべきは以下の2点です。
UIとUIロジックが密結合になっていること
特定の業務ドメインに縛られないこと
organisms
import { Title, Paragraph } from '~/atoms'
import { PriceList } from '~/molecules/PriceList'
// 価格
const Price = () => {
const { data } = fetch('https://api.endpoint')
const { quantity, unitPrice ,taxRate, shippingCost } = data;
const basePrice = quantity * unitPrice;
const price = (basePrice + shippingCost) * taxRate;
return (
<>
<Title>価格: {price}円</Title>
<Paragraph>内訳</Paragraph>
<PriceList
quantity={quantity}
taxRate={taxRate}
shippingCost={shippingCost}
/>
</>
)
}
organismsの特徴
atoms、moleculesの複合コンポーネント。
業務のドメイン情報をDOMに持つことがある。
APIとの疎通や業務ロジックを持つことがある。
organismsの実装の注意点
業務ロジックとUI(DOM)を疎結合にすることです。
organismsは上記の例のように業務ロジックや業務のドメイン情報をDOMに持ちます。
ただ上記のコード例は悪い例です。
以下のように業務ロジックとUIが密結合していると悪い点が3点あります。
- 再利用性の低下
- データ構造が見えない
- 業務ロジックをDOM上で実装できてしまう
1. 再利用性の低下
業務ロジックとUIが密結合しているのでUIを再利用したくても限られた場面でしか活用できません。
2. データ構造が見えない
コンポーネントにpropsが存在しないので最終的にどんな構造のデータをレンダリングされるのか読み取るためにはDOMを全て読み解く必要があります。上記のコードはまだシンプルですがDOMの中で条件分岐が発生したりコード量が増えるとかなりしんどくなります。
3. 業務ロジックをDOM上で実装できてしまう
業務ロジックがDOM上に実装されると、ロジックの記載場所が以下の2パターンになります。
returnより上
DOMの中
書く場所が複数ありルールも存在しないと開発する時にどちらに書くべきか迷いが生まれます。
例えば、先程提示したコードにおいて業務上の仕様が変わって会員の時は「価格が10%off」になるという業務ロジックが加わったとします。
一番手っ取り早くしようとすると最終的にレンダリングされている価格に計算処理を加える実装になりそうです。
import { Title } from '~/atoms/Title'
import { PriceList } from '~/molecules/PriceList'
// 価格
const Price = () => {
const { data } = fetch('https://api.endpoint')
- const { quantity, unitPrice ,taxRate, shippingCost } = data
+ const { quantity, unitPrice ,taxRate, shippingCost, isMember } = data
cons t basePrice = quantity cons
unitPrice t price = (basePrice + shippingCost)
taxRate
return (
<>
- <Title>価格: {price}円</Title>
+ <Title>価格: {isMember ? price * 0.9 : price}
<p>内訳</p>
<PriceList
quantity={quantity}
taxRate={taxRate}
shippingCost={shippingCost}
/>
</>
)
}
この例ではコードの行数が短いですが、実際のorganismsコンポーネントになるとコードの行数が長くなりがちで自然とこういった楽な実装に流されることが多いです。
そして何より厄介なのは上記の例のように三項演算子1つだと対して悪くなさそうに見えることです。
これに更にもう一種類、ゴールド会員が追加されるとどうでしょうか?
import { Title } from '~/atoms/Title'
import { PriceList } from '~/molecules/PriceList'
// 価格
const Price = () => {
const { data } = fetch('https://api.endpoint')
- const { quantity, unitPrice ,taxRate, shippingCost, isMember } = data
+ const { quantity, unitPrice ,taxRate, shippingCost, isMember, isGoldMember } = data
cons t basePrice = quantity cons
unitPrice t price = (basePrice + shippingCost)
taxRate
return (
<>
- <Title>価格: {isMember ? price * 0.9 : price}
+ <Title>価格: {isGoldMember
+ ? price * 0.8
+ : isMember
+ ? price * 0.9
+ : price
+ }円
<p>内訳</p>
<PriceList
quantity={quantity}
taxRate={taxRate}
shippingCost={shippingCost}
/>
</>
)
}
元々のコードでDOMに三項演算子が実装されていると自然とそこに追加する実装をしてしまうことがあると思います。
こうなると業務ロジックが
returnの上だけでなくDOMの中にも存在することになります。
ロジックの実装箇所がルールもなく複数箇所になることで可読性が一気に落ちます。
DOMを再利用するために別ファイルに切り出そうとしてもロジックを含むことで単純にDOMだけを切り出すこともできなくなります。
打開策
上記の良くない2点を打開するためには、業務ロジックとUIを疎結合にする必要があります。
具体的には、organismsの中でもコンポーネントを2つに分けます。
organisms/
├ Presentations/
│ └ Price.tsx (UIを責務としたコンポーネント)
│
└ Containers/
└ PriceContainer.tsx (業務ロジックを責務としたコンポーネント)
今後、2つのコンポーネントは以下の呼び方をします。
UIを責務としたコンポーネント: Presentational Components
業務ロジックを責務としたコンポーネント: Container Components
PresentationalComponents
// organisms/Price.tsx
import { Title } from '~/atoms/Title'
import { PriceList } from '~/molecules/PriceList'
// 価格
const Price = ({
price,
quantity,
taxRate,
shippingCost
}) => {
return (
<>
<Title>価格: {price}円</Title>
<p>内訳</p>
<PriceList
quantity={quantity}
taxRate={taxRate}
shippingCost={shippingCost}
/>
</>
)
}
PresentationalComponentsの特徴
ステートレスなコンポーネントで「
どのようにデータを表示するか?」を責務とします。
UI表示のみが責任範囲として切り出されているので別の場所で再利用も可能になります。
PresentationalCompornentsは業務ロジックを持たないため、storybook等のUIのライブラリ化も容易にできます。
propsが表示すべきデータの構造そのものになります。
PresentationalComponents実装の注意点
propsをAPIのデータ構造に依存させないことです。
あくまでも「どのようにデータを表示するか?」に注目します。
APIのデータ構造に依存するとUIの構造とデータ構造が乖離して苦しい実装を強いられたりします。
APIのデータ構造の変更が頻発し、FEの改修工数が増えるとBE側がFEの負荷を軽減するためにUIドリブンなAPI定義を意識したりします。
そうなってしまうとBE実装がUIに引っ張られて業務ドメインに沿った実装ができずFEもBEも拡張性の低い実装になったりしてしまいます。
ContainerComponents
// organisms/PriceContainer.tsx
const PriceContainer = () => {
const { data } = fetch('https://api.endpoint')
const { quantity, unitPrice ,taxRate, shippingCost } = data;
const basePrice = quantity * unitPrice;
const price = (basePrice + shippingCost) * taxRate;
return (
<Price
price={price}
quantity={quantity}
taxRate={taxRate}
shippingCost={shippingCost} />
)
}
ContainerComponentsの特徴
業務ロジックの実装に着目したコンポーネントになります。
どう表示されるかの責任はすべて
PresentationalComponentsに委ねます。
ContainerComponentsでは位置の調整や余白のためにスタイルを当てることもありません。
Presentational/Container Componentsの実装方針
organismsの中でも
PresentationalComponentsと
ContainerComponentsはディレクトリも区分けして明確に違うものとして定義しておくのが良いです。
そうすることで修正が必要な場合にどちらのコンポーネントを修正すべきかも明確に判断が付きます。
ただコンポーネントの実装を始める前から
Presentational/Container Componentsをどういった構造にすべきか設計することは難易度が非常に高いです。
まずは
Presentational Componentsをひたすら実装していき、画面まで実装するのが望ましいです。
その後APIをpagesコンポーネントで繋ぎこみます。
pagesでAPIを発行するとorganismsの
Presentational Componentsを辿って末端のatomsコンポーネントまでデータをバケツリレーしていくことになります。
この時にpropsとして受け取ったデータを無加工でそのまま更に末端のコンポーネントに渡す場面が発生するはずです。
その場面で
Container Componentsの実装を検討していくというのが手戻りを少なくできます。
結論
まとめですが、結論以下のような構成・ルールでコンポーネントを分割しました。
- atoms
- コンポーネントの最小単位。
- ロジックは持たない。
- ステートレスなコンポーネント。
- システム全体で流用できる。
- molecules
- atoms、moleculesの複合コンポーネント。
- UIロジックを持つことがある。
- ステートレスなコンポーネント。
- システム全体で流用できる。
- organisms
- atoms、moleculesの複合コンポーネント。
- 業務のドメイン情報をDOMに持つことがある。
- そのためシステム全体で流用できるとは限らない。
- APIとの疎通や業務ロジックを持つことがある。
- PresentationalComponentsとContainerComponentsを分ける。
得た恩恵
Atomic designの区分が明確化
atoms/moleculesの再利用性・拡張性の担保
organismsのUIと業務ロジックの責務をコンポーネント単位で分離
全体を通してどこに何を実装すべきかが判断できるようになり無理な実装が生まれない仕組みを実現できました。
おわりに
いかがでしたでしょうか。
上記のコンポーネント開発の構成がどのプロジェクトでも上手く行くとは限らないですが、何か1つでも参考になる箇所があれば幸いです。私の所属するHRテック事業部は発足してまだ日が浅く、プロダクトの状況も0-1フェーズにあります。なのでこういったどういう構成で開発を進めるべきかなどを検討・決定していける機会が多いです。この記事をご覧になり、この事業部を一緒に盛り上げてみたいなと思う方が1人でも増えれば嬉しく思います!(詳しくは
こちら)
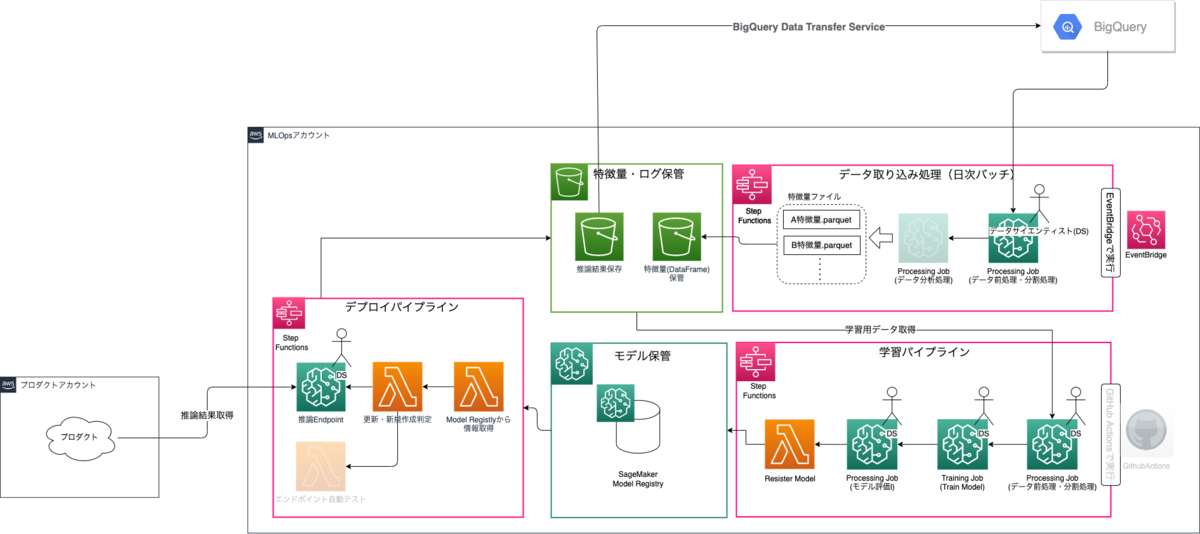
 ※「モダンフロントエンド開発者に求められるスキルとは」より引用
※「モダンフロントエンド開発者に求められるスキルとは」より引用