
はじめに
こんにちは、テクノロジー戦略室の新城です。私は2022年6月に中途入社し、入社してまだ半年ですがMLOpsの推進という仕事を担当しています。
現在レバレジーズではレバテックダイレクトの求人マッチ度判定のような、レコメンドシステムを多くのサービスで活用しています。
一方で機械学習モデルを本番運用したはいいが、データサイエンティストがモデルの改善フローを回しにくく、再トレーニングしたモデルのデプロイが頻繁にできないといった問題が顕在化してきました。
そこで、今回は社内営業支援ツールにおいてMLOpsを導入し実際にデータサイエンティストがモデルの改善プロセスを回せるようになったその事例を紹介できればと思います。
背景
レバレジーズのMLシステムはMLOps レベル0と言われる状態に近く、データサイエンティストがモデルを作成し、プロダクトへモデルを一度組み込むとその後の改善は行いにくく、プロダクトでのモデル品質も充分に確認できない状態でした。
あるプロダクトでは、図中のModel Servingの部分でプロダクションエンジニアがプロダクトの要求レベルに沿うように前処理の高速化等を行っており、トレーニング時と推論時に前処理が異なっている状態(Training-Serving Skewが起こっている状態)でモデルの更新に双方のエンジニアに工数がかかってしまう状況でした。
このような状況では、データサイエンティストは他のエンジニアの手を借りないとデプロイが出来ないという制約から、軽微なモデルの改善を手軽に行うことができません。加えて、レコメンドにおけるMLモデルはその品質を保つために、定期的に再学習を行い、トレンドを学習する必要があります。しかし、再学習時のデプロイ毎に双方のエンジニアに工数がかかる状態は好ましくありません。
そこで今回はデータサイエンティストが主導してモデルの改善・デプロイを行うことができる環境を整えることで、プロダクトエンジニアの工数を削減し、モデルの改善に積極的に取り組めるような仕組みづくりを目指しました。

MLプラットフォームの導入
上記の状態を改善するため、今回AWS SageMakerやGCP Vertex AIに代表されるようなMLプラットフォームの導入を検討しSageMakerを採用することになりました。データの分析から学習、モデルデプロイを一手に担ってくれるプラットフォームを導入することでデータサイエンティスト主導の機械学習モデル開発・デプロイができるようになることが狙いです。 またMLパイプラインを用途ごとに設けることでMLOps レベル1の状態に少しでも近づけることを目標としています。
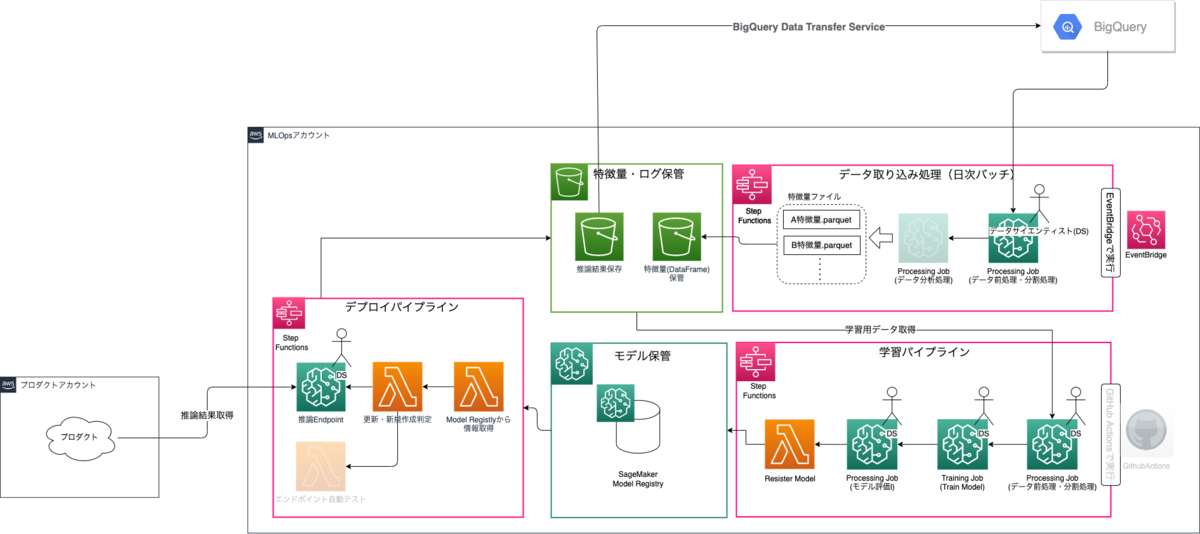
構成図
今回はAWS SageMakerとStep Functions DataScience SDKを用いてMLパイプラインを構築しました。グレーアウトしている部分は今後の実装を予定している部分です。
図中の棒人間がいる箇所をデータサイエンティストに実装してもらい、後はパイプラインを実行していけばプロダクトに使用する図中左下のエンドポイントまでデプロイが完了します。
全体構成だけではわかりにくいと思うので各パイプラインの役割をそれぞれ見ていければと思います。
1. データ取り込みパイプライン
まずはデータ取り込み処理部分について順を追って説明をしていきます。
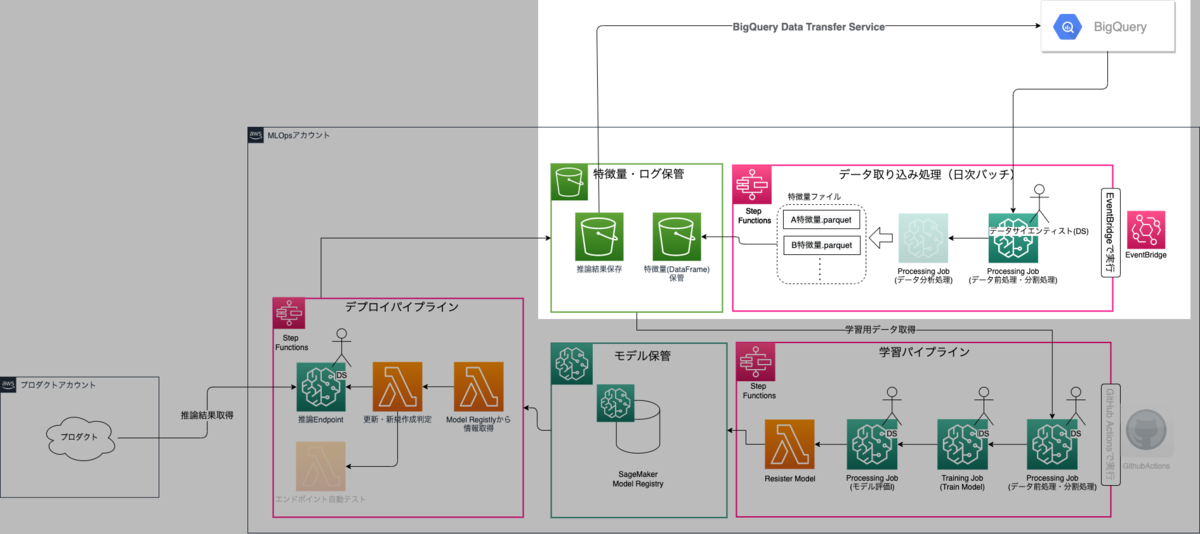
1.1. Event Bridgeの起動 学習・推論に使用するデータをBigQueryから定期的に読み込むためにEvent BrigeでStep Functionsの起動をしています。
1.2. データ取得と前処理 レバレジーズではデータウェアハウスとしてBigQueryを採用しており、データサイエンティストはここから任意のデータを取得・前処理・データフレーム化して使用します。 少しややこしいのですが、ここでの前処理と後述する学習パイプラインの前処理は異なっており、統計的な特徴量(平均値や分散値など)等の推論毎に作成する必要のない特徴量を予め作成し、推論時にこれらのDataFrameを予め読み込んでおくことで推論処理の高速化を図っています。
1.3. データの品質チェック(将来実装) 取得するデータの特徴量ドリフト検知といった品質チェックや定期実行毎の特徴量の推移等を出力できるとデータサイエンティストに気づきを与えることができるのではないかと検討中です。
2. 学習パイプライン
S3に用意されたデータを元に学習から評価までを行っています。Lambda Stepではモデルとその評価値をSageMaker Model Registryへ登録しています。
ここでの処理は一般的に紹介されている学習パイプラインとほぼ同等と思って頂けたらと思います。

3. デプロイパイプライン
ModelRegistryへ登録されたモデルをデプロイするパイプラインです。

3.1. Model情報取得(Lambda) Step Functionsへの入力となるモデルパッケージ情報とバージョン情報を元にModel Registryから必要な情報を取り出しています
3.2. Endpoint新規作成・更新判定 このLambdaは単にEndpointの新規作成か更新かを判定するものです。入力されたEndpointNameを元に判定しています。
3.3. 推論Endpointの立ち上げ Endpoint立ち上げ時に前述のデータ取り込みパイプラインで作成したDataFrameを読み込んでおり、推論時に都度作成する必要のない特徴量はこちらを活用しています。 またデータキャプチャ設定で保存された推論結果をS3からBigQueryへ日次で転送しておりデータサイエンティストが推論結果をBigQuery上で解析できるようにしています。
3.4. エンドポイントに対しての自動テスト(未実装) データサイエンティストがプロダクトに関わるエンドポイントの実装とデプロイを行うということで、心理的安全性の担保ためにここの実装は必要だと考えています。
改善できたこと
データサイエンティスト主導のモデル改善フローの実行
データサイエンティストが用意したパイプライン実行用のPython Notebookを使用して、モデルの改善を任意のタイミングでより容易に行うことができました。実際にSageMakerを導入してから短期間で複数回モデル変更のデプロイをデータサイエンティスト主導で行っておりその効果はあったのかなと思います。 一方で実行が手動なのは変わりなく、どのファイルを変更したらどのパイプラインを実行すれば良いといったフローはかなり煩雑なので、現在は変更に対応するパイプラインが自動実行されるといった自動化に着手中です。
Training-Serving Skewの改善
こちらのルールの通り、コードを再利用する実装を事前にデータサイエンティストと進めたことで、基本的にはデータサイエンティストの変更のみでモデルのデプロイを行う仕組みを整えることができました。一方でエンドポイントのレスポンス速度は常に保証する必要があるため、前述した自動テストでのチェックや後述の前処理高速化に取り組んでいきたいと考えています。
試したが今回は盛り込めなかったもの
前処理の高速化(ApachBeam等の導入)
今回はリアルタイム推論だったのですが、比較的前処理の量も少なく、特に工夫せずともプロダクト要件を満たす処理時間に収めることができたため学習コストの観点から導入はしませんでした。 但し、今後時間のかかる前処理やストリーミングで捌かないといけないデータが必要となった際にはApachBeamといったバッチとストリーム処理が可能なデータ処理パイプラインを導入しなければいけないと考えています。導入の際には推論時のみだけでなく、学習側もきちんと共通化できるように考えて実装していきたいです。
Feature Storeの導入
S3へ特徴量データを保存している部分をFeature Storeに置き換えたかったのですが、定期実行時にFeature Storeへ書き込むと今回のデータ量では書き込み量が多く、想定以上の料金がかかってしまうことがわかりました。データの差分のみを登録する仕組みを作る案も出ましたが、定期実行ごとにDataFrameを作りバージョン管理できた方が便利なため今回は採用を見送っています。上記の前処理高速化と関連してストリーミングデータを扱う際にはまた必要だと考えています。
今後の施策
MLOps レベル1への移行やより良いモデル開発体験を目指して以下のことを行っていきたいです。
- パイプラインや運用プロセスの自動化
- データサイエンティストがGitHub上で改修ブランチを切ったら前処理・学習・評価(ABテスト)まで自動で行われる仕組みを目指したい
- モデル評価機構の確立
- 特徴量や特徴量寄与度に違いがないか監視(ドリフト検知)
- モデルレジストリへ登録しているモデルへのリアルタイム評価の反映
- もしこのモデルがデプロイされたらこのくらいのパフォーマンスを出すだろうといった予測を与えられたら
- 前処理高速化やFeature Storeの導入
- 今回は必要性がなかったため断念したが、今後に向けて実装を検討していきたい
最後に
今回の記事ではSageMakerを導入しデータサイエンティストがモデルの改善プロセスを回せるようになったその事例を紹介しました。MLOpsの導入と言い切るにはまだまだ改善すべきことが多いですが、まずは初めの一歩を踏み出すことができたのかなと思います。
また、これらの実装には入社してまだ半年の私を支えてくれた、データ戦略室のデータサイエンティストの理解と協力無くしては実現できませんでした。 このように、レバレジーズには年次や経験を問わず、主体的に取り組める環境が整っています。ご興味のある方は、以下のリンクから是非ご応募ください!