 こんにちは!レバレジーズ株式会社テクノロジー戦略室SREチームの蒲生です。
Datadog導入と監視のイネイブリングによってインフラ監視、アラート運用を開発者向けに民主化した事例を紹介します!!
こんにちは!レバレジーズ株式会社テクノロジー戦略室SREチームの蒲生です。
Datadog導入と監視のイネイブリングによってインフラ監視、アラート運用を開発者向けに民主化した事例を紹介します!!
この記事で伝えたいこと
- インフラ監視をみんなでやるのいいぞ
- サービスのスケールに柔軟に対応できるぞ
- インフラのことまで考えて開発ができるぞ
↑の状態を達成するためにやったこと
- 監視のイネイブリング
- 監視による開発者への負荷軽減
インフラ構成が簡単に肥大化、複雑化する時代になってきました。 日々成長する事業を支えるために増えていく新規のマイクロサービスやスケールアウトされるサーバーに対して監視の設定をしていくことに悩んだ経験はないでしょうか。 私が主に担当しているレバテックの開発では、インフラ監視に開発者が携われる体制にすることで高速に変化していくインフラ構成に対して柔軟に対応できるようになりました。
当時の課題
当時の開発では以下のような前提と課題を抱えていました。
前提
アーキテクチャ
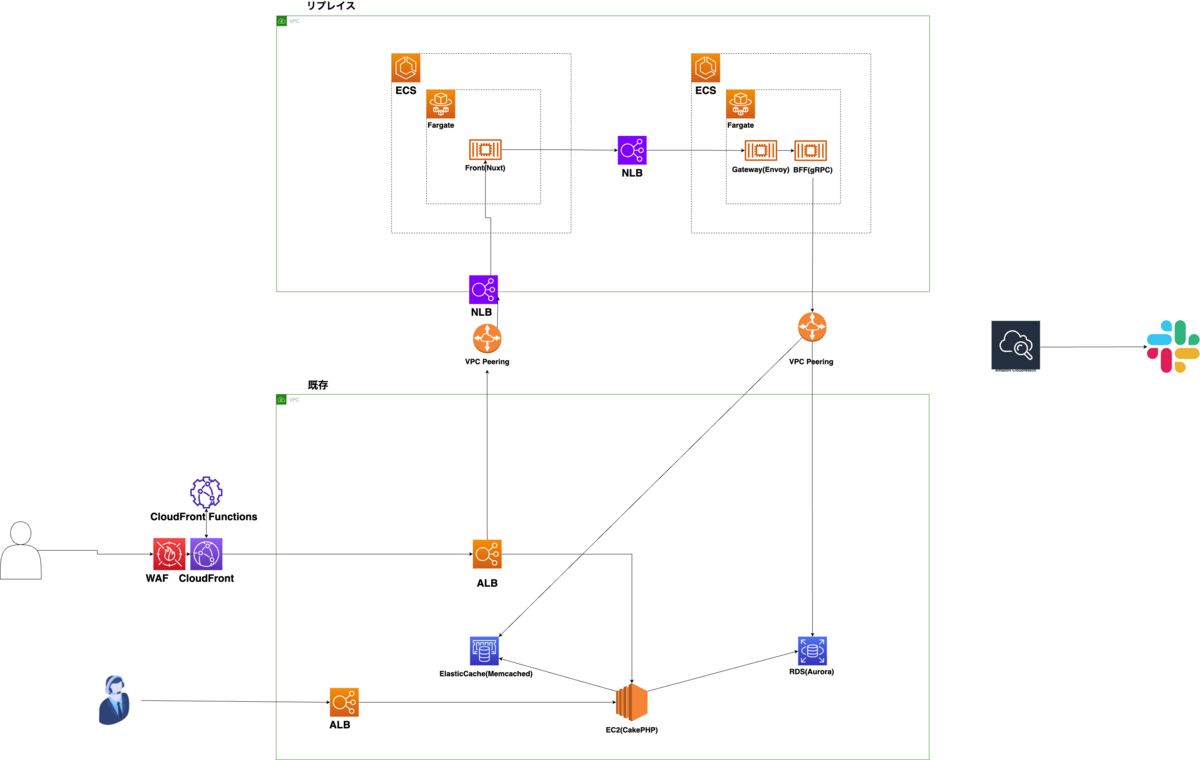
レバテックではAWSのEC2のモノリスアプリケーションからECSなどサーバーレス環境にマイクロサービスとして切り出していくリプレイスプロジェクトが進行中でした。
監視体制
当時の監視ツールはAWS CloudWatchを使用していて、CloudWatch AlarmやLambdaからメトリクスのアラートやエラーログをSlackに流すようにしていました。
課題
開発スピードに対して監視の対応が追いついていない
前提にある通りECSやLambdaを利用してマイクロサービスに切り出していくため インフラのリソースがどんどん増えていく状態に監視の設定や体制が追いついておらず、計測したいデータが取得できていませんでした。
インフラ関係のインシデントの多さ
アクセス負荷やデータ量の変化、不適切な実装によるインフラリソースへの負荷が原因でインシデントが発生してしまうケースが散見されていました。
インシデント発生時にかかる調査工数の肥大化
インシデントが発生したときにログやメトリクスを利用して調査を開始するのですが 先に述べたように取得できていないデータがあったり監視体制が整っていないこともあり 調査工数が肥大化して解決までに時間がかかっていました。
課題分析
当時の課題を以下のようにそれぞれ原因分析してみました。
監視対応の属人化
監視の設定や運用ができる人が社内で限られていて 追加されていくインフラの多さに対してボトルネックになっていました。 設定にかかる負荷が高いため設定漏れなどで取得していないデータがありました。 実際の作業に関する暗黙知だけでなくどの項目に監視の設定をすればいいのか、メトリクスの相関をどう見ればいいのかなどの知見の共有が足りていない状態だったと思います。
インフラリソースの使用状況の曖昧さ
実装者からみてリソースの使用状況が把握しづらい体制でした。 インフラのリソースが普段どのくらい使用されているのかを意識するタイミングが少なく、リリース後しばらく経って変化するメトリクスなどには気づきにくい状態だったと思います。 また当時のCloudWatchだと使い慣れている人でないとデータやメトリクスへのアクセス性が悪く、使用状況をぱっと確認できる手段がなかったのも曖昧になった原因となっていました。
調査時に発生するコミュニケーションコストの肥大化
当時監視設定やメトリクスのモニタリングをSREチームが担当することが多かったのですが、実際に開発をしているのは開発チームというサイロ化した状態でした。 インシデントが発生した際に異変に気づき調査を開始するのはSREチームだけど 何がリリースされたのか、コードがどう実装されているのかまで深く把握していないので開発チームと連携を取る必要があり、そこでコミュニケーションコストが発生していました。
解決策
当時知識があったわけではないですが今から振り返るとDevOpsのCALMSフレームワークでいうC(Culture)、A(Automation)、S(Sharing)を特に意識して解決策を考えたように思えます。
- 監視設定、運用の負荷軽減
インフラ監視設定の自動/半自動化を進めることで設定漏れと全体の工数を減らし、インフラ監視の知識がない開発者でも設定ができるような状態にすることで属人化の解消を目指しました。 またDatadogの導入によってメトリクスやログの可視性を上げてデータへのアクセス性を向上させました。
- 監視のイネイブリング
開発チームと一緒にメトリクスやアラートを確認する機会を定期的に作って、開発してリリースしたものがインフラやサービスにどう影響を与えているかを把握してもらうようにしました。 それによって開発者が監視設定や普段のモニタリングを行えるようにして、インシデント発生時に開発者の中である程度対応が完結できるようにしました。
具体的な施策
Datadog導入による監視設定、運用の負荷軽減
普段の設定、運用にかかる負荷を軽減するために 監視SaaSツールであるDatadogの導入を行うことでインフラ監視設定の自動/半自動化による設定工数の削減とメトリクス、ログの可視性向上を進めました。 それまで使用していたCloudWatchでは当時だと取得したいメトリクスの不足や統一的なアラート設定がしにくい、ダッシュボードのUIの使いにくさなどの課題があり、自動/半自動化を進めにくい状態だったのでこのタイミングでツールの切り替えを決断しました。

クラウドのリソースに監視用のタグをつけるだけで自動でDatadogにデータを送れるようにし、 新規のサーバーやマイクロサービスに対してはIaCツールによってコード化することで設定にかかる負荷を軽減して開発者によってインフラ監視設定を自走できるようにしました。 それによってSREチームやインフラに詳しい人がいなくても監視設定が進むようになりました。 また監視用のダッシュボードとログ検索機能を用意して、開発者が確認したいタイミングでぱっと見れるようにデータへのアクセス性と可視性を向上させました。
定期的なメトリクス確認会実施による監視のイネイブリング
開発者に監視の知見を深めてもらって運用できる状態にするために メトリクスダッシュボードを使って開発チームと一緒にメトリクス確認会を週次で実施しました。
まず先述したDatadogを使って各サービスごとにダッシュボードを作成し、開発者がいつでもインフラのメトリクスやログを確認できる状態にして
そのダッシュボードを利用して週次で開発チームと週次でメトリクスやアラートを確認するメトリクス確認会を実施しました。

はじめはファシリテーションを私が行ってメトリクスの異常値や状態化したアラートなど会の中で確認したほうがいいものをシェアして、それらに対する調査や改善などのネクストアクションを出すまでを話す時間を作りました。 それによってリリースされたどのコードがインフラやユーザーに影響を及ぼしたかメトリクスやアラートの確認を通して開発者が把握して異変が見つかったら修正行動に移せるようになりました。

開発者がある程度慣れてきたらファシリテーションをだんだん委譲させることで、SREチーム抜きで会が回るようになっていきました。 今ではインシデント発生時のアラートへの1次アクションは開発チームが行っています。
まとめ
監視設定の負荷が軽減されて開発者が運用に関わりやすい状態になり、サービスのスケールにインフラ監視が追従できるようになりました。 さらに、開発者が週次でメトリクスやアラートを確認する機会を作ることで、開発者が普段の開発がインフラレイヤに及ぼしている影響を把握し、アラートへのアクションを開発チーム内である程度完結できるようになりました。
インフラ監視の民主化の重要性を示すひとつの例となったのではないでしょうか。 なによりSREチームの私としては開発チームの方と共通言語を使ってサービスの課題について話し合えるようになって仕事が楽しくなりましたし 開発チームが独自に監視やログの設計を見直している活動を見たときは嬉しくなりました。
改めてここで伝えたいことのおさらい
- インフラ監視をみんなでやるのいいぞ
- サービスのスケールに柔軟に対応できるぞ
- インフラのことまで考えて開発ができるぞ
今回は監視、アラートに関する取り組みでしたが他にも色々な取り組みを通じてSREチームとしてプロダクトの信頼性を保ちながらより質の高いリリースを可能な限り早くできる状態を目指して頑張っていきます!!
レバレジーズではサービスの信頼性を高める活動をしていきたいエンジニアを募集しています。 興味のある方のご応募をお待ちしています!