
はじめに
レバレジーズ株式会社 レバウェル開発部 バックエンドチームサブリーダーの山口です。
総合転職サービス「レバウェル」は
- 転職アドバイザー(転職エージェント)
- スカウトサービス
- 求人サイト
を1つのサービスで利用できるアプリケーションです。
2024年2月よりCMを放送することとなり、
このマス広告を打つために、広告効果によって増加するユーザーとその負荷に耐えることができるかの検討と対策を行いました。
本記事では、私たちがどのような視点で速度改善に取り組んだのか、そしてその結果として特定のAPIの処理速度を82倍向上させた経緯をご紹介します。
レバウェルについて
はじめにレバウェルの基本情報と今回取り組む課題の背景について簡単にご説明します。
技術スタック
今回の内容に関係するレバウェルの技術スタックをご紹介します。
- 言語
- TypeScript
- フレームワーク
- Next.js, NestJS
- ライブラリ
- Apollo Server
- インフラストラクチャ
- AWS(ECS, RDS)
- Vercel
- API規格
- GraphQL
導入済みの性能対策
ISR(Incremental Static Regeneration)
レバウェルでは初期リリース時にISR(Incremental Static Regeneration)を採用しました。 対象はSEOの観点で重要かつリアルタイム性が高くないページです。
これによりアプリ全体を再ビルドすることなくデータの変化を定期的にページに反映することができます。
DataLoader
GraphQLはクライアントが必要とするデータを必要な分だけ一度に取得できるという強みがあります。 しかしその一方で、データを取得する際にN+1問題というパフォーマンスに関する問題も抱えがちです。今回はN+1問題に関する詳細な説明は省略しますが、この問題を解決するためにDataLoaderを導入しています。 DataLoaderを用いて各リレーションごとのバッチ処理を行い、SQLの実行回数を削減しています。
増加するユーザーとその負荷に耐えられるか
webアプリケーションにおいて表示速度は離脱率と密接な関係にあり、性能を評価する上で重要な指標となります。
どんなにコンテンツが素晴らしくとも、表示速度が遅いと見てもらうことすらできません。

マス広告を打つということは、必然的にユーザー数が短期間で増加します。 この負荷によって性能が悪化すると、ユーザーにプロダクトの価値を提供することができなくなってしまいます。 そのような事態を防ぐべく、速度改善の必要性を判断し、必要な対策を講じることとしました。
速度改善の必要性はどう判断する?
速度改善の必要性があるかどうかの判断基準として以下を定めました。
予想されるAPI実行頻度において性能目標を達成しているか
これを判断するために、以下の2点を定義する必要があります。
- 予想されるAPI実行頻度
- 性能目標
これらの数値に基づいて負荷テストを行い、実行結果が性能目標を満たしていなければ速度改善の必要があると判断することができます。
API実行頻度の見積もり
今回はマス広告の効果によるリクエスト数の増加を考慮する必要があります。
実際の計算の流れは以下の通りです。*1
とある集計期間における1分間あたりのリクエストレート(単位:RPM)が
5 RPMであった時について考える。1時間あたりのリクエスト数は以下で表すことができる。
TotalRPH = RPM * 60
つまり300 RPHとなる。また、集計期間におけるログインユーザー数が50人だった時、 ログインしていないユーザー数をX人とする。 このとき、一人当たりに発生する1時間のリクエスト数は
RPH-per-person = TotalRPH / (50 + X)と表すことができる。 ただし、今回はより余裕を持った対策を行いたいため、ログインユーザーを分母としてリクエスト数を計算することとする。 つまり一人当たりに発生する1時間のリクエスト数は
RPH-per-person = TotalRPH / 50
となり6 RPHとなる。この時、広告の掲載によって大量のユーザー増加が見込まれる場合について考える。 TVCMを放映した場合、「CMを認知してもらう」という目的では個人全体視聴率でおよそ500GRPが目安とされている。 *2
GRP500の場合3000万人前後に視聴されるというシミュレーション結果があるため、本検証でもこの数値を使用する。*3次にCTRが仮に0.2%だとすると約6万人前後がTVCM放映期間中に流入することになる。
TVCM放映期間がスポットCMの契約最短期間である一週間と仮定すると、
1時間当たりの新規流入数 = 60000 / (24 x 7) ≒ 357
増加するリクエスト数(毎分) = (RPH-per-person * 357) / 60
と表すことができる。
この結果35.7 RPMとなる。既存のリクエストレートと合算し、性能を担保をすべき最低限のリクエスト数は
41.7 RPM ≒ 0.7 RPS
となる。
性能目標
今回レバウェルでは、以下のことから改善対象APIをp95 1秒以下でレスポンスすることを性能目標として定めました。
- 主要機能を改善対象とする(後述)
- 本サイトにメディア的性質がある
- SEO要件からより速い描画速度が求められる
API実行レートはTVCM配信後に波のようなスパイクが来ることを想定し、見積もりよりかなり余裕を持たせて5 RPS でテストすることにします。
どこを改善する?
主要機能の分析
さて、ここまでで速度改善の必要性を判断するための基準は準備できました。 次にやるべきことは、その基準に基づいて必要性の可否を判断することです。 速度改善の取り組みは時間がかかることが予想されるため、全ての機能について改善することは費用対効果的によろしくありません。 そこでレバウェルでは、まずAPIの実行量を観測し、速度改善に値するものを抽出することにしました。
API実行量の観測
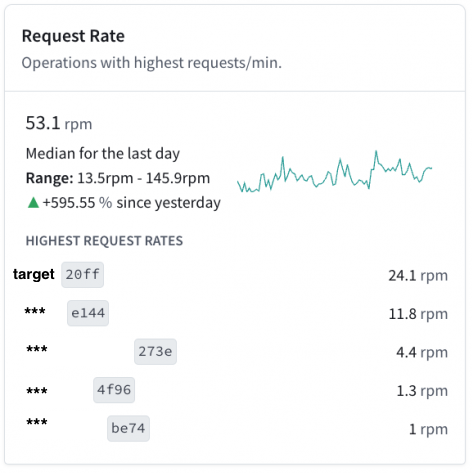
今回はApollo StudioのAPI統計情報から最も実行されているGraphQL Operationを探しました。
Insightsから統計情報を確認します。 リクエストレートを確認してみると、上位2つが多く実行されていることがわかります。 対応する画面を確認したところレバウェルの中核となる部分と対応しており、システム的にこれらの二つが主要機能と言えます。
本記事では最もレートが高かったリクエスト名をtarget(仮)、 それに対応するAPI名をgetTargetInfo(仮)として説明します。
負荷テストによる速度調査
特定した画面およびAPIについて速度改善の必要性があるかを判断します。 判断基準は決定しているため、そちらに従って負荷テストを行います。テストランナーはk6を使用します。
まず先ほど特定したリクエストレートの高いGraphQL Operationを使用している画面について試験を行います。 対象画面を含めた合計4つの画面に仮想ユーザー数100で繰り返しアクセスすることとします。
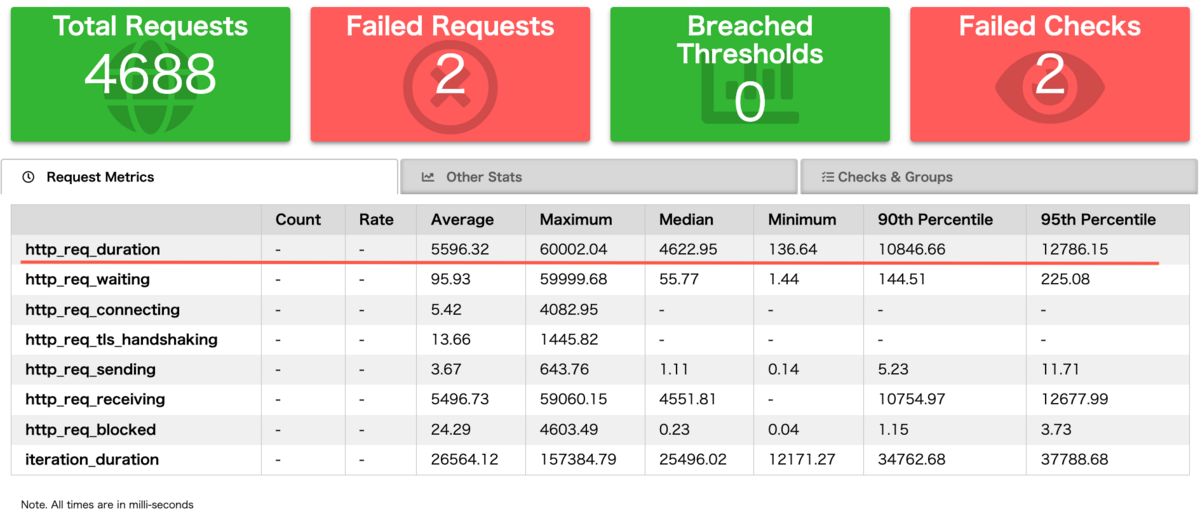
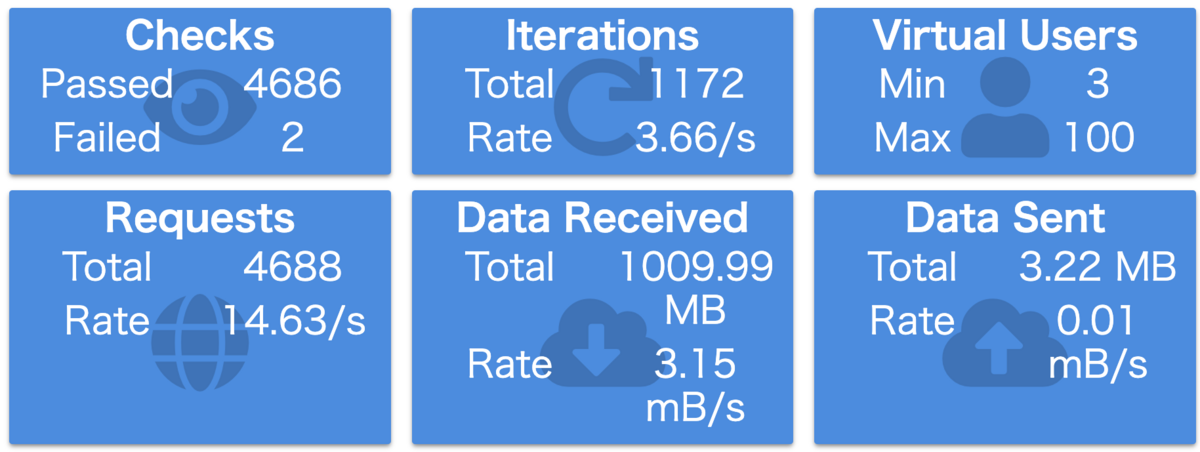
http_req_duration(p95)が12秒超という非常によろしくない結果です。
次にバックエンドサーバーに対し、画面で要求しているフィールドと全く同一な状態でAPIを実行します。
getTargetInfo(仮)を5 RPSで実行した結果
avg=7.44s min=430.08ms med=8.62s max=9.73s p(90)=9.47s p(95)=9.53s
これはp95 1秒以下でレスポンスするという性能目標を満たしていないため、改善する必要があると判断しました。
どうやって改善する?
基本的なwebアプリケーションであればSQLが最もボトルネックになりやすい箇所です。 そのためまずSQLに注目することにしました。
以下の流れに従って調査します。
1. ボトルネックとなっているSQLを見つける.
2. そのSQLが遅い原因を理解する.
3. 改善する.
4. 改善したSQLを測定する.
どういったSQLが実行されているか
対象のAPIを実行した時、どのようなSQLが実行されるのかをチェックします。 ここで明らかな問題(N+1問題や初歩的なWHEREでの絞り忘れなど)があれば、まずはそれを解決できるからです。
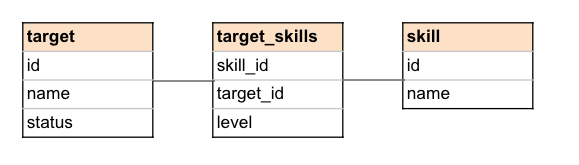
今回は以下のようなテーブル構成とGraphQLのqueryを例とします。
query target($getTagetInfoId: Int!) {
getTagetInfo(id: $getTagetInfoId) {
id
name
status
targetSkills {
skillId
level
skill{
id
name
}
}
}
}
targetテーブルに連なるリレーションはTypeORMのLazy Relationsによって解決します。
この場合、要求されたリレーションのフィールド1つにつき1件のSQLが実行されます。 この例の場合、以下のように少なくとも3回実行されるイメージです。
1. 指定されたIDを持つターゲット情報を取得する。
これはgetTagetInfoフィールドに対応します。
SELECT * FROM target WHERE id = $1;
2. そのターゲットに関連するtargetSkillsを取得する。
これはtargetSkillsフィールドに対応します。
SELECT * FROM target_skills WHERE target_id = $1;
3. 各targetSkillsエントリに関連するskillを取得する。
これはskillフィールドに対応します。
targetSkillsの各エントリに対して1つのクエリが実行されるため、このステップでのクエリ数はtargetSkillsのエントリ数に依存します。
SELECT * FROM skills WHERE id = $1;
実際にレバウェルの該当ページを開いてGraphQLリクエストを発生させたところ、およそ100件を超えるSQLが実行されていました。
これ自体はGraphQLの設計思想上、「要求されたものだけを取得する」ということで間違っていません。また、前述(導入済みの性能対策)の通りDataLoaderを用いた各リレーションごとのバッチ処理は行っています。 しかし該当ページは描画要件の都合により、取得しなければならないフィールドが多く、DataLoaderによる性能改善には限界がありました。
約100テーブルに及ぶ膨大なリレーション情報が必要となると、データ解決手法によってはパフォーマンス問題が発生する恐れがあります。 またコネクションプールの枯渇、ネットワークコストの増加による負荷増の問題も考えられます。
Slow Queryはあるのか
次にSlow Queryがあるかを調査します。 仮に実行時間の大半を占めるようなSlow Queryがあり、それを解消すれば良いなら100件のSQLを実行する形のままでも目下の障害にはならないからです。
今回はpostgresのpg_stat_statementsモジュールを使って分析しました。
対象APIを呼ぶページを開き、以下のSQLでSlow Queryを抽出します
SELECT * FROM pg_stat_statements order by total_time desc limit 100;
今回は個別のクエリは軽いようで、 一番かかっているもので26msほどでした。 これはindexや個別のSQL最適化が意味をなさず、100件の分割されたクエリを何らかの方法でまとめなければならないことを意味しています。
改善方針決定
次は100件のSQLを1つのSQLにまとめるなら、どのようにすれば良いのか考えます。 もちろん単純に100テーブルをJOINしてしまうと結果セットがデカルト積となり、爆発的な量となってしまうので実現不可能です。
そこで今回は以下の点に注目しました。
- それぞれのSQLには複雑な条件がない。単純な外部キー結合がメイン
- 結果セットの多さが問題
ここから考えられる対処法には以下の2つがあると考えました。
1. テーブル設計を変える
2. SQL上のテクニックで結果セットの数を削減する
1の方法は最も高品質なものができる解決法ですが、今回対象となるテーブルはレバウェルの根本となっているため、リプレイスに近い形になってしまうことから見送りました。2の方法はあまり見ない方法ですが、今回のケースではJSONB_AGG集約関数とJSONB_BUILD_OBJECT関数を用いることで結果セットを減らせそうです。
一方でSQLが複雑なものとなり保守性が低下してしまうのがデメリットです。
今回はメリット・デメリットを総合的に判断し2の方法を採用することにしました。
実装
100件のSQLを1つのSQLにまとめる
結果セット数を抑えつつ100件のSQLを1つにまとめるために、大きく4つのSQLの文法を使用しました。
- Common Table Expressions
postgresではWITH ASの構文で表されます。一時的な名前付き結果セット、つまりサブクエリの結果を生成するために使用されます。主な利点は、複雑なクエリをより読みやすくかつ管理しやすくすることです。また、同じサブクエリを一度書いてそれを再利用することができます。
参考:https://www.postgresql.jp/docs/9.5/queries-with.html
- LATERAL
LATERALを付与したサブクエリはそれより前のFROM項目を参照できるようになります。今回はLEFT JOIN LATERALの形で使用しました。これによってサブクエリが外部クエリの行に依存する場合に、それぞれの行に対して異なる結果セットを生成できます。そして、LEFT JOINの性質上サブクエリが結果を返さない場合、nullとして処理されます。
参考:https://www.postgresql.jp/document/9.6/html/queries-table-expressions.html
- JSONB_BUILD_OBJECT
キーと値のペアからJSONBオブジェクトを作成するための関数です。この関数は任意の数の引数を取り、それらを交互にキーと値として扱います。行のデータをJSON形式で出力する必要がある場合など、データを柔軟に扱いたい時に便利です。
参考:https://www.postgresql.jp/document/13/html/functions-json.html
- JSONB_AGG
引数を受け取り、JSONB配列に集約する関数です。
参考:https://www.postgresql.jp/docs/9.5/functions-aggregate.html
詳細な内容はPostgreSQL公式をご参考ください。
実装SQLはこのような形になります。
WITH r_target AS ( SELECT * FROM target t WHERE t.id = $1 AND t.status = 'active' ), s AS ( SELECT ts.target_id, JSONB_AGG( JSONB_BUILD_OBJECT( 'skill', s.obj, 'level', ts.level ) ) as target_skills_info FROM target_skills ts INNER JOIN LATERAL( SELECT JSONB_BUILD_OBJECT( 'id', s.id, 'name', s.name ) AS obj FROM skill s WHERE s.id = ts.skill_id ) s ON true WHERE ts.target_id = (SELECT id FROM r_target) GROUP BY ts.target_id ) SELECT * FROM r_target LEFT JOIN s ON s.target_id = r_target.id
実行結果イメージ
| id | name | status | target_id | target_skills_info |
|---|---|---|---|---|
| 1 | hoge | active | 1 | [{‘skill’: {‘id’: 1 ,‘name’: ‘skill1’}, ‘level’: 5}, … ] |
実際には上記の対応を全てのリレーションに適用し、そのSQLを用いることで効果の検証を行います。
補足
nullハンドリング
上述のSQLでLATERALを使用した理由としてネストしたオブジェクトのnullハンドリングがあります。 例えば、
-- v.hogeは存在しない SELECT JSONB_BUILD_OBJECT( 'v_id', v.id, 'hoge', JSONB_BUILD_OBJECT('name', h.name) ) FROM v LEFT JOIN hoge h ON h.id = v.hoge_id
この結果は{v_id: x, hoge: {name: null}} となります。
この時に、GraphQLで「v.hogeはnullableだが、hoge.nameはnot nullable」のような設定をしている場合は少々困ってしまいます。
そのため以下のようにしてnullハンドリングを行いました。
-- v.hogeは存在しない SELECT JSONB_BUILD_OBJECT( 'v_id', v.id, 'hoge', h.obj ) FROM v LEFT JOIN LATERAL( SELECT JSONB_BUILD_OBJECT('name', h.name) AS obj FROM hoge h WHERE h.id = v.hoge_id ) AS h ON true
LATERALを使用することで、サブクエリが各vの行に対して独立して評価されます。そしてLEFT JOINであるため、h.id = v.hoge_id を満たさない場合はobjがnullとして結合されます。
従って{v_id: x, hoge: null}となり、一般的にイメージされるnullableなオブジェクトになります。
設計方針
今回選択した手法はGraphQLの大きな強みである「不要なデータフェッチを防ぐ」にやや反するものとなっています。 つまりGraphQLとSQLが分離できておらず、オーバーフェッチが発生し得る設計となっています。 その上で本方針を選択した理由として以下があります。
- 該当APIの使用目的が限定されており、実際にはオーバーフェッチが発生しない
- 工数の都合によりEager Loading的な設計を選択せざるを得なかった
プロダクト全体としてはLazy Loadingを使用し「クライアントが必要とするデータを必要な分だけ取得する」という設計方針で実装されています。
対策後の計測
API処理速度の検証
対策の効果を検証するため、上記のSQLを適用した新しいAPIに対して負荷テストを行います。 条件は前回と同様に5 RPS, 同一要求フィールド、同一のレコードです。
avg=59.98ms min=36.26ms med=50.89ms max=201.09ms p(90)=96.25ms p(95)=115.55ms
以前の結果
avg=7.44s min=430.08ms med=8.62s max=9.73s p(90)=9.47s p(95)=9.53s
レスポンスタイム(p95)で約82倍の高速化に成功しており、かなり改善をすることができました。
おわりに
以上がレバウェルにおける速度改善の取り組みとなります。 このような性能改善の取り組みは、コストなどの兼ね合いから最も理想的な改善策を選択できないこともあると思います。 しかしながら、状況に応じて最適な対策を打つことで高い効果を得ることができます。
本記事が少しでも参考となれば幸いです! 最後までお読みいただきありがとうございました。
現在、私たちと一緒に社会課題に挑戦するエンジニアを募集中です! ご興味のある方はぜひ採用サイトをご覧ください!